Calibrating Conditional Risk
Authors: Yikai Wang
1. The Problem: Global Calibration Is Too Coarse for Instance-level Decisions
Most uncertainty methods report a global statement such as “the model is calibrated on average.” That is not the question a downstream decision-maker actually faces. In practice, the question is local:
- for this specific input
x, how wrong is the predictor expected to be? - should the system predict automatically, ask for human help, or reject the sample entirely?
This paper formalizes that question through the conditional risk function
where f_hat is the predictor and ell is the task loss. The object g(x) is the expected loss conditioned on the input itself, not on the population as a whole.
That quantity is useful because it can directly drive downstream actions. High g(x) means the model is unreliable on this instance, which is exactly the kind of signal needed in active learning, selective prediction, and learning-to-defer systems.
2. Formal Setup in Classification and Regression
The paper studies both classification and regression.
In the classification case, if , then the conditional risk is
In the regression case, if the conditional response distribution has density , then
This looks simple, but it is a distinct problem from ordinary probability calibration. Probability calibration estimates class probabilities. Conditional risk calibration estimates expected loss, which is a downstream decision object rather than a predictive probability.
The paper’s first conceptual contribution is to separate these two notions cleanly while still proving that they are related in classification.
3. Two Ways to Estimate Conditional Risk
The paper analyzes two estimation routes.
3.1 Regression-based estimation
The direct approach is to treat the realized loss as a regression target. For each sample , define
and fit a regressor on the dataset . This yields the empirical objective
This is attractive because it turns the problem into a standard supervised regression task with familiar generalization tools.
3.2 Calibration-based estimation
In classification, the paper shows a second route. Instead of regressing directly on realized losses, estimate the full conditional probability vector and plug it into
This approach is only available in classification, but it is theoretically more interpretable because it exposes how better probability estimation improves conditional risk estimation.
4. The Main Theoretical Result: Calibration-based Estimation Can Be Better
The paper proves that the regression-based formulation inherits the standard excess-risk behavior of ordinary regression. That is useful, but the more interesting result is on the calibration-based side.
Under weak realizability and proper classification loss, the calibration-based estimator is tied directly to the conditional probability model. The paper then shows that this leads to a tighter way to control conditional risk than the direct regression route, and in favorable classification settings the calibration-based method can outperform the regression-based one both theoretically and empirically.
In plain terms, the theory says:
- estimating
g(x)directly is possible; - but in classification, estimating
p(y | x)well can be an even better route to estimatingg(x); - therefore conditional risk calibration is related to probability calibration, yet not reducible to it.
This is the part of the paper that makes the problem mathematically interesting rather than merely application-driven.
5. Classification Experiments: Better Probability Models Give Better Conditional Risk Estimates
The classification experiments use CIFAR-10 with predictors of varying strength, including CNN, ResNet, and EfficientNet variants. The calibrators are also varied in strength, so the experiments can test both the predictor side and the conditional-risk estimator side.

The main empirical findings are aligned with the theory:
- calibration-based methods outperform regression-based estimators across predictors;
- stronger probability estimators lead to better conditional-risk estimation;
- group calibration methods such as Platt scaling can still be weaker than estimators targeted at the individual-input level.
The last point matters because it shows why ordinary post-hoc calibration is not enough. Conditional risk estimation is an instance-level object, so methods optimized for coarse calibration can distort the signal needed for defer-or-predict decisions.
6. Why the Problem Matters Operationally: Learning to Defer and Regression with Rejection
The paper’s downstream testbed is learning to defer. In this setting, the system predicts on easy instances and defers difficult ones to a human expert at some cost c.
For regression with rejection, the pipeline can be described as follows:
- predictor
f_hat(x)proposes a response; - conditional-risk estimator
g_theta(x)estimates expected loss; - rejector
r(x)chooses whether to accept the prediction or defer.
The value of conditional risk is that g_theta(x) becomes the natural control signal. If the estimated risk exceeds a threshold tied to the deferral cost, the system should escalate.
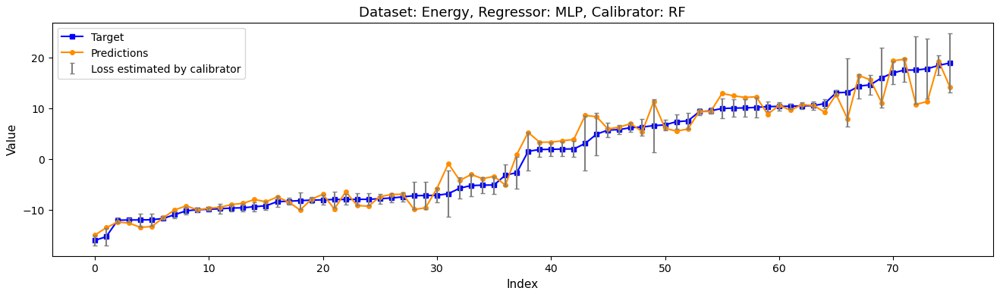
This is the most practical section of the paper because it converts conditional risk from an abstract quantity into a control variable with operational meaning.
7. Regression with Rejection: Better Calibrators Lower Downstream Loss
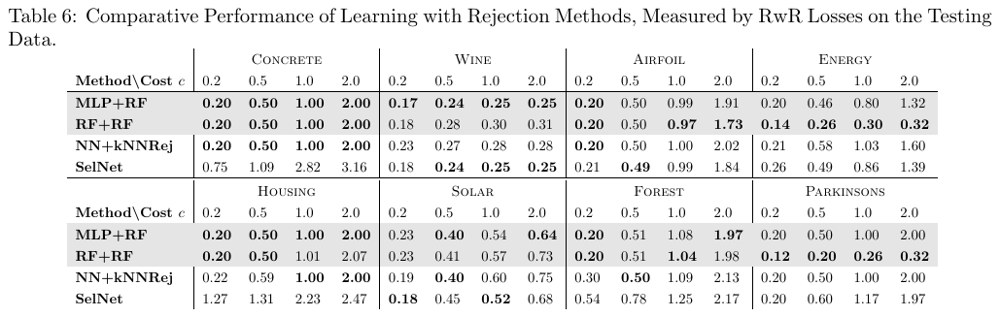
The regression experiments use multiple UCI datasets and compare several predictor-calibrator combinations, including linear regression, random forest, MLP-based predictors, and random-forest calibrators.

The main message is not that one universal calibrator wins everywhere. The deeper finding is that lower conditional-risk estimation error tends to translate into lower regression-with-rejection loss. In the reported experiments, random-forest calibrators are especially strong, and combinations such as MLP+RF and RF+RF match or outperform prior regression-with-rejection baselines on many datasets.
8. Why This Paper Matters
The strongest point of this paper is that it identifies the right object for reject/defer decisions. The downstream system does not need a generic confidence score. It needs an estimate of the expected loss on this specific input. Once the problem is stated that way, conditional risk becomes the natural control variable for selective prediction, learning to defer, and rejection-based pipelines.
What makes the paper technically sharp is not just the definition. It proves that in classification there are two genuinely different estimation routes:
- regress directly on realized losses;
- or estimate conditional class probabilities and then convert them into expected loss.
The theoretical and empirical results then line up around one concrete message:
- Classification: calibration-based estimators can dominate direct regression-based estimators because they preserve more structure from the underlying predictive distribution.
- Decision systems: better conditional-risk estimates produce better reject/defer behavior, not just nicer uncertainty plots.
- Interpretation: “well calibrated on average” is too weak when the action is taken per instance.
So the paper is not really a note about post-hoc calibration. It is a paper about how to turn predictive uncertainty into an actionable instance-level decision signal and how to estimate that signal in a mathematically principled way.