REMAST Real-time Emotion-based Music Arrangement with Soft Transition
Authors: Zihao Wang, Le Ma, Chen Zhang, Bo Han, Yikai Wang, Xinyi Chen, Haorong Hong, Wenbo Liu, Xinda Wu, Kejun Zhang
Paper: IEEE Xplore - Document 10734159
1. Problem Setting: Real-time Emotion Fit Is Not Enough
REMAST studies a more delicate problem than ordinary controllable music generation. The goal is not simply to generate music that matches a target emotion at one instant. The target emotion changes over time, so the system must satisfy two constraints simultaneously:
- real-time fit: the generated segment should match the current target emotion;
- soft transition: the emotional trajectory should evolve smoothly instead of jumping abruptly.
This is naturally expressed in the valence-arousal space. If is the target emotion at time , and is the generated musical segment, then a successful system should keep the recognized emotion of close to while also controlling the change from to .
A compact formulation is:
where m_t is the source melody segment. Existing methods were relatively good at the first term and much weaker on the second.

2. The Main Idea: Fuse the Previous Emotional State with the Current One
REMAST is organized in two phases.
- Music emotion recognition: estimate the emotion of the previously generated segment.
- Music generation: fuse the recognized previous emotion with the current target emotion, then arrange the next segment from the input melody.
If the recognized previous emotion is and the user’s current target emotion is , then the generation stage uses a fused control variable
rather than conditioning only on . That is the mechanism that operationalizes soft transition.
This is the right inductive bias for the problem. Emotional control is treated as trajectory tracking rather than per-frame classification.
3. The Recognition Model Uses Music Theory Features, Not Only Raw Tokens
The recognition phase uses a multilayer perceptron architecture that consumes both music content and four theory-driven feature families:
- Harmonic Color (HC)
- Rhythm Pattern (RP)
- Contour Factor (CF)
- Form Factor (FF)
The model predicts a fine-grained sequence of valence-arousal values for short music segments. In effect, it estimates from the previously generated music.

These features are not decorative additions. They encode concrete musical hypotheses about emotion:
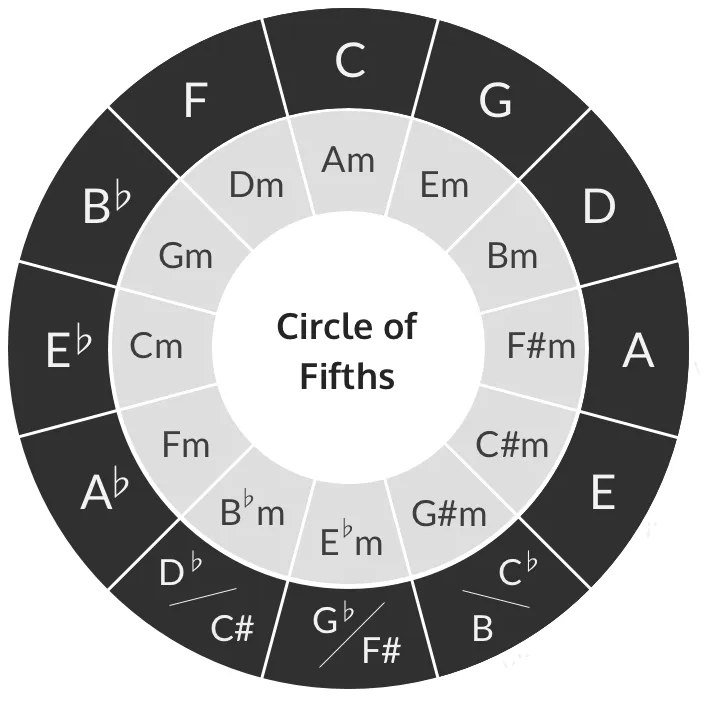
- Harmonic Color quantifies harmonic freshness through relations on the circle of fifths.
- Rhythm Pattern summarizes note-duration behavior that affects arousal and momentum.
- Contour Factor captures temporal direction, extrema, and concavity of melodic motion.
- Form Factor captures repetition, structural section similarity, and paragraph-level organization.
The paper also uses semi-supervised learning so that unlabeled music can contribute to training while reducing the subjectivity of manual emotion annotations. Conceptually, the total training loss is of the form
which lets the recognition model regularize noisy labels with broader musical structure.
4. Downsampling Is a Data and Control Solution, Not Just a Speed Trick
One of the more interesting contributions in REMAST is the downsampling arrangement pipeline. Emotion-labeled arrangement pairs are scarce, and exact high-resolution arrangement can overconstrain the generator. The paper therefore downsamples the original melody, generates at that coarser level, and then reconstructs a richer arrangement.
If is the original melody and is its downsampled version, the generation stage is better understood as
where s_t includes the music-theory features. The downsampling factor becomes a control knob for the similarity-emotion trade-off:
- finer granularity preserves source similarity;
- coarser granularity gives the model more room to reshape emotion.
This is a strong design decision because it attacks both the data scarcity issue and the control smoothness issue with one representation change.
5. What the Experiments Show
The paper evaluates REMAST on eleven open-source music datasets and measures both objective and subjective quality. The subjective study focuses on four aspects that matter in practice:
- coherence;
- softness of transition;
- similarity to the original music;
- fit to the target emotion.
This is important because objective fit alone can be misleading. The authors explicitly note a mismatch between statistical emotion-fit metrics and human perception: a system may numerically track target emotion while still sounding jarring because the transition is abrupt.
REMAST performs well because it improves the perceptual side of the problem. According to the reported results:
- it outperforms comparison methods on coherence and similarity;
- it achieves stronger softness scores when target emotion changes abruptly;
- its downsampling setup labeled as the best configuration in the paper gives the strongest combined objective-subjective balance;
- ablation shows all four theory features matter, with Harmonic Color having the largest impact when removed.
That last point is useful. It indicates the model is not merely benefiting from more parameters; it is benefiting from the specific structure of the added emotional features.
6. The Anxiety-relief Application Matters
The paper goes beyond offline evaluation and tests REMAST in an anxiety-relief scenario. Therapists define target emotional trajectories for intervention, and the system adapts familiar melodies instead of abruptly switching songs.
This is an excellent stress test for the method because the application amplifies exactly the failure mode the paper is trying to solve. Sudden musical changes can be uncomfortable or counterproductive in therapy. REMAST’s soft-transition mechanism is therefore not a cosmetic improvement but directly tied to the downstream objective.
The reported application results show that REMAST performs better than both the original music and real-time recommendation baselines in emotional regulation. That is strong evidence that the method’s contribution is practical, not only architectural.
7. Why This Paper Is Technically Interesting
REMAST’s real contribution is conceptual: it reframes real-time emotion-based arrangement as trajectory control under structural constraints.
The system is interesting for three reasons:
- It separates emotion recognition from generation and closes the loop between them.
- It uses music-theory features to stabilize emotional interpretation.
- It uses downsampling as a principled representation choice that improves controllability, data efficiency, and transition smoothness.
The main limitation is that the feature design and recognition pipeline still encode domain assumptions from symbolic music theory. But for a structured problem like emotion-based arrangement, that bias is arguably an advantage rather than a liability.
Publication
- Journal: IEEE Transactions on Affective Computing
- Year: 2025
- Volume/Issue: 16(2)
- Pages: 1016-1030
- DOI: 10.1109/TAFFC.2024.3486224