Risk Profiling and Modulation for LLMs
Authors: Yikai Wang, Xiaocheng Li, Guanting Chen
Paper: arXiv:2509.23058v3
Presentation: INFORMS Annual Meeting talk, 2025
1. Why Risk Preference Is a Real Alignment Problem
Large language models are increasingly used in domains where uncertainty is central: portfolio choice, medical decision support, resource allocation, and policy analysis. In these settings, accuracy alone is not enough. Two models with similar task accuracy may behave very differently when confronted with risky choices.
This paper argues that an LLM should be treated not only as a predictor, but also as a decision-maker with an implicit risk profile. The main questions are:
- what risk preference is already encoded in a given model;
- how stable that preference is across prompting or post-training;
- whether the preference can be modulated toward a target user or institution profile.
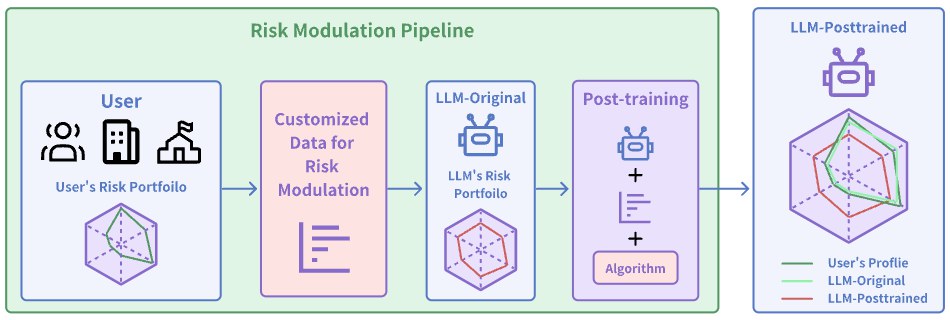
This framing is stronger than generic persona prompting. It moves from vague style control to utility-theoretic characterization.
2. Data Collection: From Qualitative Questionnaires to Quantitative Lotteries
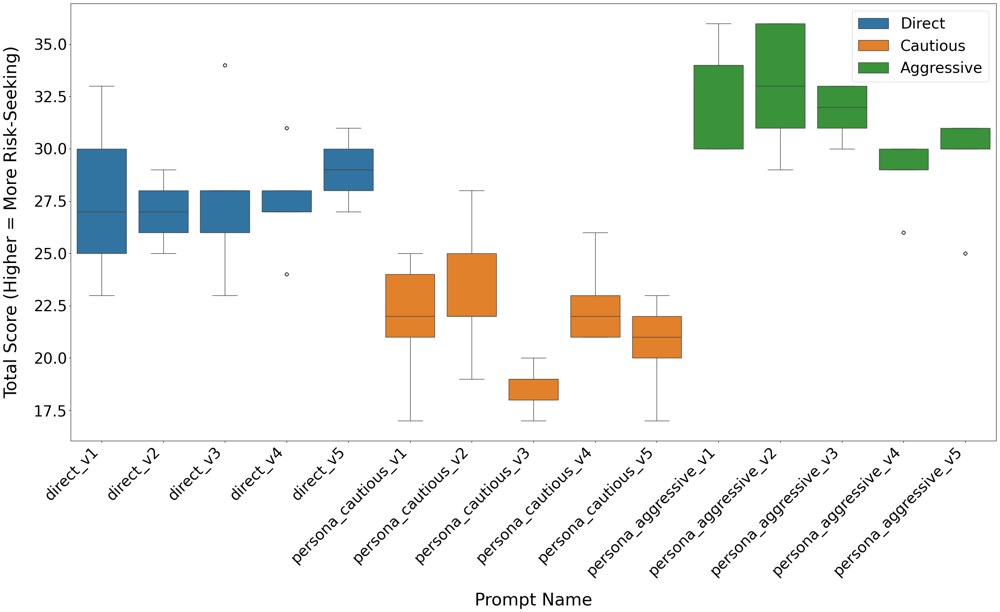
The paper starts with the 13-item Grable and Lytton risk-tolerance questionnaire to obtain a coarse, human-interpretable first pass at model behavior. Under direct prompts, aggressive prompts, and cautious prompts, most models shift in the expected qualitative direction, but this only gives a rough ordinal picture.
To get a sharper estimate, the paper builds a lottery-choice dataset. Each example presents a risky option and a safer option :
where y_i = 1 if the model picks the risky option and 0 otherwise.
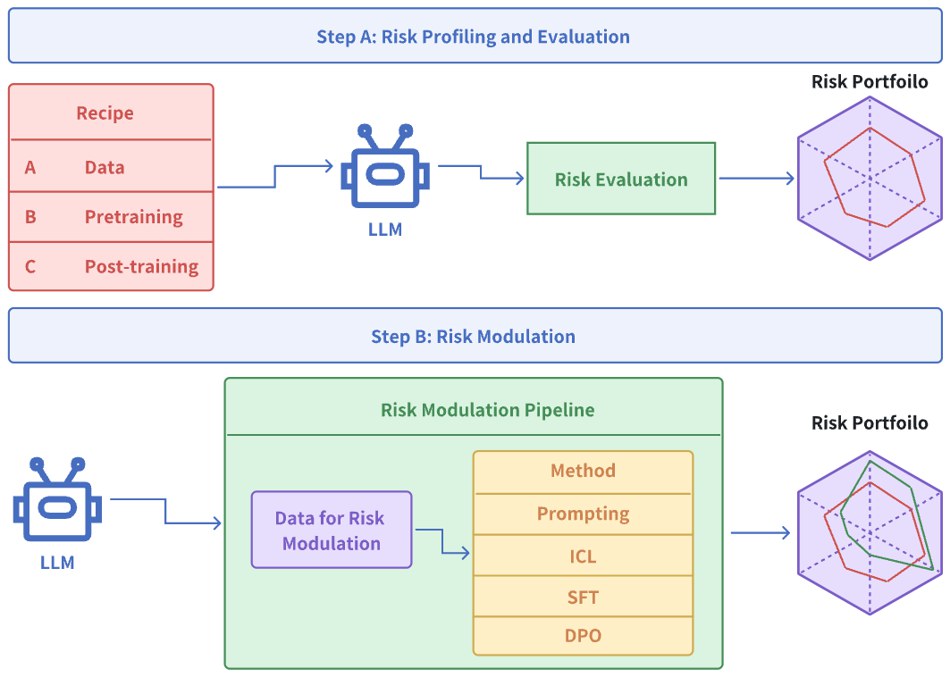
The paper considers both same-expectation and different-expectation lotteries, so the resulting profile is not tied to one narrow prompting pattern.
3. Utility-theoretic Profiling: A Model Is Not Interpretable Until the Fit Is Good
The most important methodological choice in the paper is that it does not assume in advance that every LLM behaves like a classical expected-utility agent. Instead, it fits many candidate utility classes and checks goodness of fit first.
For a parameterized utility function , the expected utilities of the risky and safe options are
and under the random utility model the probability of choosing the risky option is
where is an inverse-temperature parameter.
The paper then fits utility families such as linear utility, CRRA, CARA, HARA, prospect theory value functions, Epstein-Zin utility, and piecewise Friedman-Savage style utilities using Bayesian inference with MCMC. This matters because many earlier discussions about LLM risk behavior jump straight from a few observed answers to behavioral interpretation. Here the authors explicitly insist that interpretation is only valid after the fitted utility model predicts held-out choices reasonably well.
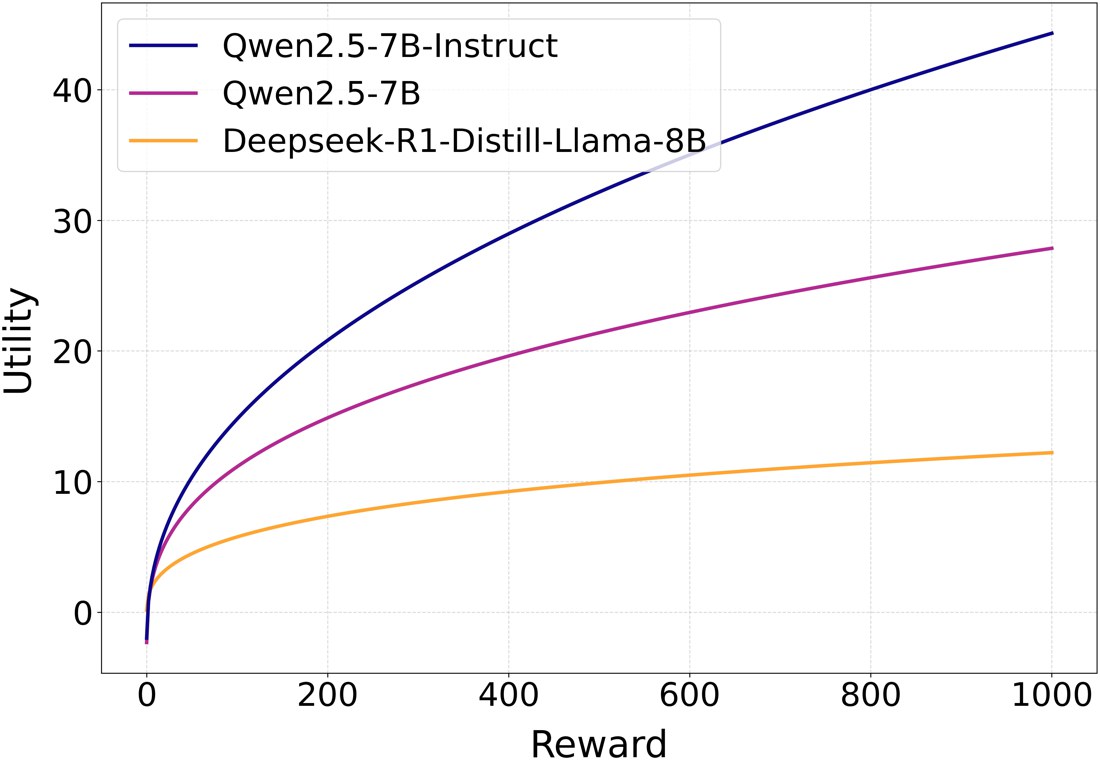
The interesting empirical outcome is that instruction-tuned models often admit cleaner utility-based fits than pre-trained or RLHF-aligned variants. Another notable result is that the best-fitting utility is often not a simple concave function, which suggests that many LLMs do not follow textbook diminishing marginal utility in any straightforward way.
4. Prompting Can Move Behavior Qualitatively, But Not Reliably Quantitatively
The questionnaire experiments show that prompting matters. Aggressive prompts make most models more risk seeking, and cautious prompts make them more conservative. But that does not mean prompting is a robust calibration method.
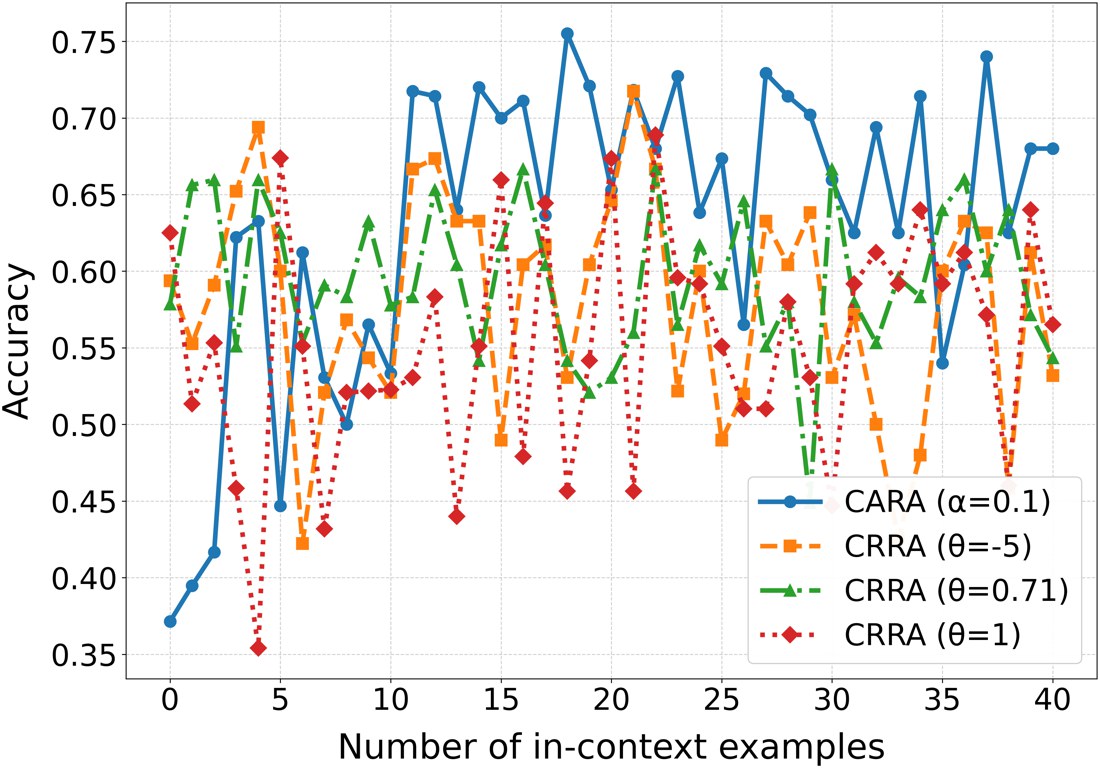
The paper demonstrates this more carefully using in-context learning for risk modulation. Suppose we want the LLM to imitate a target utility function . Prompting and in-context examples can nudge behavior in the desired direction, but the shift is unstable and deteriorates out of sample.
That negative result is important. It separates surface steering from structural modulation. A model that sounds more aggressive in one prompt may still fail to implement the target risk rule on new lottery questions.
5. Post-training Is the Only Method That Produces Stable Modulation
The paper then studies three modulation strategies:
- prompt engineering;
- in-context learning;
- post-training via SFT and DPO.
For supervised fine-tuning, the objective is the standard next-token loss on the target choice label:
For direct preference optimization, the model is trained to prefer the target option over the alternative:
The paper tests target utility functions from CRRA, CARA, and prospect-theory families. The main result is clear: post-training works; in-context prompting does not.
Among post-training methods, DPO is consistently stronger than SFT, especially for more structured target utilities such as CRRA and prospect theory. This is a valuable finding because the task is inherently preference-based: the model is not learning a factual label so much as a choice rule.
6. Transfer and Robustness: Does the New Risk Profile Survive Outside the Training Distribution?
A useful contribution of the paper is that it does not stop at binary lottery accuracy. It evaluates post-trained models in a 4-choice setting and also tests them on the DOSPERT questionnaire, which measures risk-taking across financial, health/safety, recreational, ethical, and social domains.
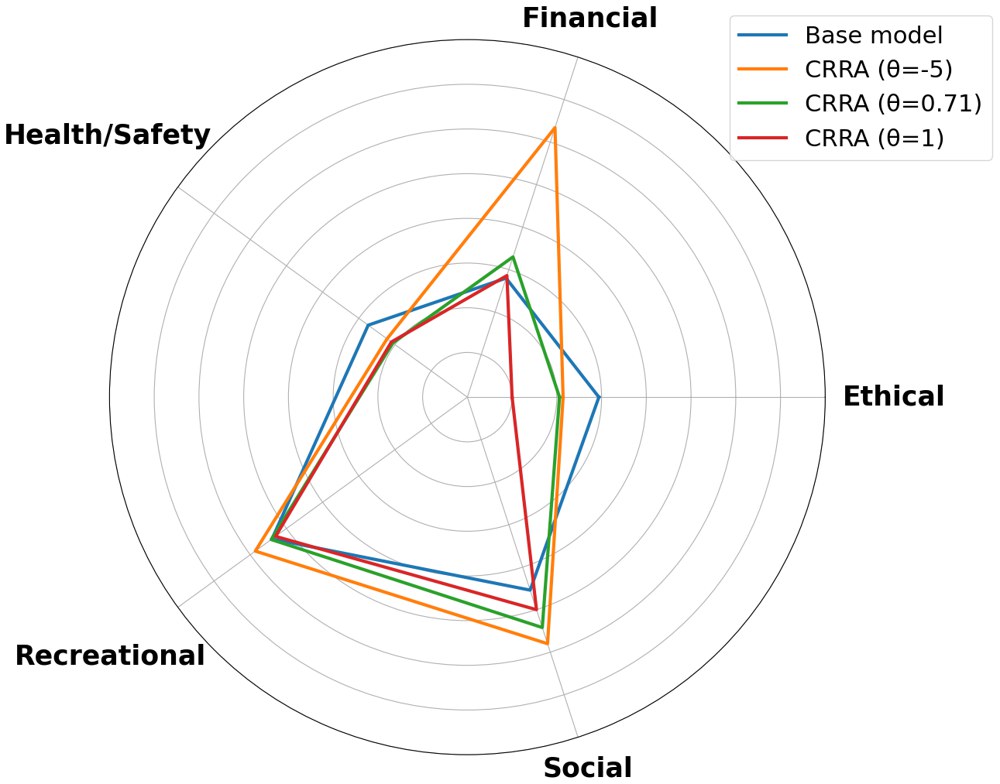
The out-of-distribution story is nuanced. The risk-seeking DPO models do become more aggressive on downstream financial decisions, but the shift is strongest in domains closest to the training data. That is exactly what one would expect if the alignment signal is real rather than merely an artifact of the benchmark.
This tells us that risk preference is partly modulable and partly domain-shaped. That is a more realistic conclusion than claiming a universal global risk knob.
7. Why This Paper Matters
The paper makes three contributions that I think are genuinely important.
- It turns LLM risk behavior into a measurable object rather than an anecdotal observation.
- It shows that utility fitting can be meaningful for some models, but only after goodness-of-fit is checked carefully.
- It provides evidence that DPO-style post-training can create auditable, relatively stable shifts in risk behavior.
The practical implication is straightforward: if an LLM is used in high-stakes decision support, we should not ask only whether it is accurate. We should also ask what type of risky decision-maker it is, whether that profile matches the deployment context, and whether the profile can be moved in a controlled way.
A limitation is that the experiments are still built around stylized lotteries and survey instruments. But as a first step toward behavioral alignment for decision-making LLMs, this is exactly the right level of formalization.