SongDriver Real-time Music Accompaniment Generation without Logical Latency nor Exposure Bias
Authors: Zihao Wang, Kejun Zhang, Yuxing Wang, Chen Zhang, Qihao Liang, Pengfei Yu, Yongsheng Feng, Wenbo Liu, Yikai Wang, Yuntao Bao, Yiheng Yang
Paper: ACM DOI 10.1145/3503161.3548368
1. The Core Technical Problem
Real-time accompaniment generation has a very specific failure mode: the model must react to live melody input without waiting, but it also needs enough long-range structure to sound musically coherent. Prior systems usually solved only one side of this trade-off.
If a model waits for more melody context before producing accompaniment, then the generated accompaniment is logically late. If a model predicts the next accompaniment event directly from its own previous predictions, then it avoids delay but suffers from exposure bias: one bad chord choice can contaminate the following steps.
A useful way to formalize the problem is to separate planning from playback. Let denote incoming melody information at time , let denote a cached harmonic plan, and let denote the actually played accompaniment. SongDriver is built around the idea that these should not be generated by the same mechanism.
where denotes global musical features extracted from a longer history. The key is that the second stage conditions on the cached arrangement signal rather than on its own previously generated accompaniment.

2. Why the Two-phase Design Removes the Main Failure Modes
The paper’s central idea is a two-phase pipeline.
In the arrangement phase, a Transformer reads the recent melody and predicts chord-level structure in real time. These chords are not played immediately. Instead, they are cached as a harmonic plan for the next phase.
In the prediction phase, a linear-chain CRF predicts the playable chord for the upcoming melody using the cached chord sequence and previous melody context. Because the played accompaniment is generated for the upcoming melody rather than for already-passed melody, the system achieves what the paper calls zero logical latency.
At the same time, the model avoids the usual autoregressive drift. The prediction stage does not keep conditioning on its own past accompaniment outputs. It conditions on the cached arrangement signal, which is more stable and structurally informed.
This is a stronger design than a single end-to-end autoregressive generator for two reasons:
- The Transformer is used where long-range dependency modeling matters most: harmonic arrangement.
- The CRF is used where low-latency sequential decoding matters most: local playable chord prediction.
In other words, SongDriver does not ask one model to solve both global structure and low-latency execution at once.
3. Global Musical Features Are What Make the Short Context Work
A streaming system cannot keep feeding the full history into the model indefinitely. The paper therefore adds four handcrafted but musically meaningful long-range features so that the Transformer can still access phrase-level structure even when the local input window is short.
The feature vector can be summarized as
The four added signals are:
- Weighted notes: notes emphasized by accent, syncopation, or duration.
- Weighted factors: a chord-like summary extracted from longer melody fragments using a ChordMap and edit-cost comparison.
- Structural chords: stable non-inversion chords tied to the current mode, used to preserve harmonic backbone.
- Terminal chords: cadence-related markers that signal phrase endings and larger structural boundaries.
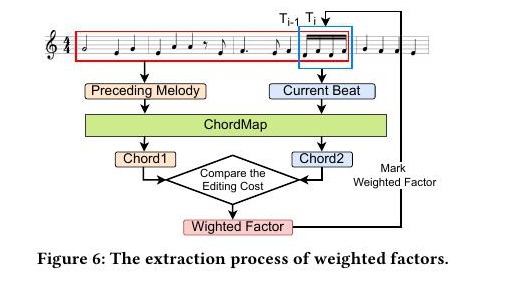
The weighted-factor module is the most concrete example of how the paper injects long-range musical knowledge into a streaming pipeline. The system first constructs a ChordMap that spans simple triads up to richer chord types, then compares the active note collection against candidate chords and chooses the lowest-cost harmonic summary for the current beat. That summary is much easier for the Transformer to condition on than a raw note stream, because it already compresses the local melody into a coarse harmonic hypothesis.
This part matters because it explains why the system is not merely a latency hack. The paper explicitly compensates for the information loss caused by beat-level streaming. Without these feature channels, the model would be forced to approximate phrase structure from a tiny rolling window.
4. The CRF and Texture Engine Turn Harmonic Plans into Playable Music
The prediction stage uses a linear-chain CRF. In standard form, the model defines
where is the chord state at time , is the unary compatibility between the current context and candidate chord, and is the transition potential between consecutive chord states.
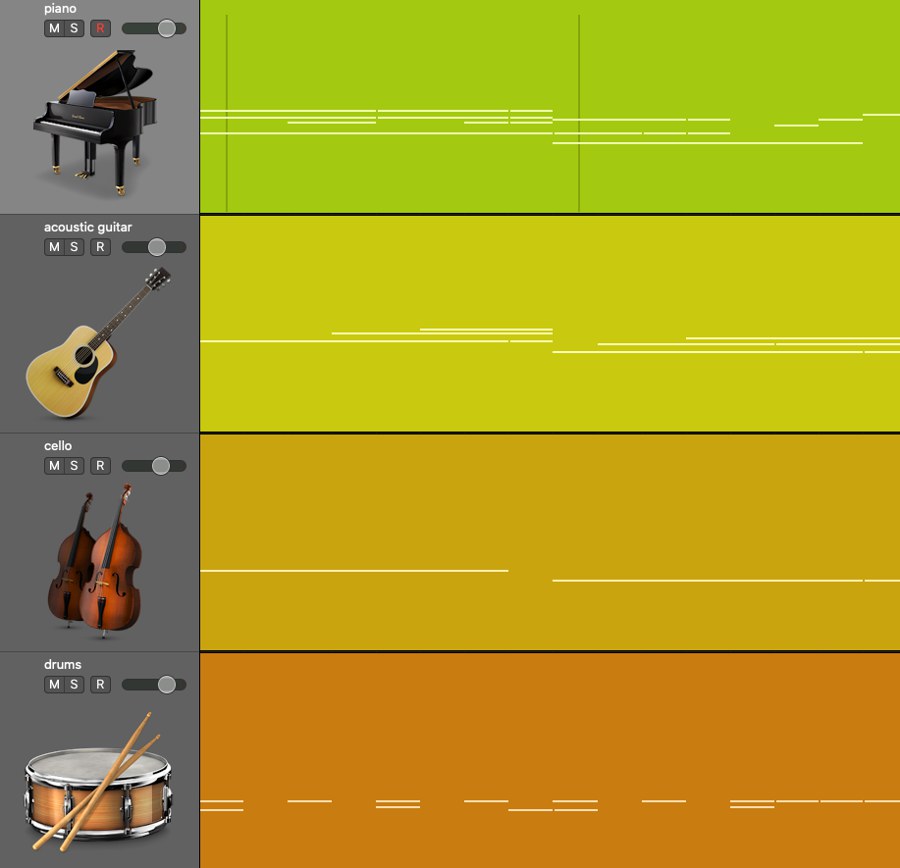
After chord prediction, SongDriver still has to solve another practical problem: a chord sequence is not yet a convincing accompaniment. The system therefore adds a texture generation layer that maps predicted harmony into multi-track accompaniment patterns for piano, guitar, cello, drums, and related parts.
These texture patterns are switched according to phrase structure and cadence information. Decorative textures are used around phrase transitions, while more regular patterns cycle inside phrases. This is important because it moves the system from harmonic correctness to actual musical usability in live accompaniment.
5. Experimental Setup and What the Results Actually Show
The paper trains SongDriver on open-source datasets together with the authors’ aiSong dataset built from Chinese-style modern pop scores. The reported setup uses 18,367 clips for training and 850 clips for testing. The arrangement phase is a lightweight Transformer with one encoder-decoder pair, while the prediction phase uses CRF++ for chord decoding.
Evaluation is not limited to one metric. The paper reports:
- objective metrics comparing generated accompaniment against ground truth;
- subjective metrics measuring harmonic appropriateness, progression coherence, and perceived synchronization;
- comparisons against both latency models and bias models rather than only against one baseline family.
The strongest result is not just that SongDriver scores well. It is that the Transformer-CRF pairing consistently beats alternative pairings such as Transformer-Markov, Transformer-LSTM, RNN-CRF, and HMM-CRF. That supports the paper’s architectural claim that global planning and low-latency execution should be handled by different modules.
The paper’s own Table 4 is useful because it shows that SongDriver stays very close to ground truth on the metrics the authors care about most:
| Reported quantity | SongDriver |
|---|---|
CTnCTR delta from ground truth | -0.010 |
PCS delta from ground truth | -0.015 |
MCTD delta from ground truth | -0.004 |
HS delta from ground truth | +0.008 |
Subjective MAH score | 3.92 |
Subjective CPC score | 4.08 |
Subjective MHS score | 4.14 |
Those numbers matter because the paper explicitly argues that CTnCTR and MCTD are tied to how well accompaniment stays synchronized with the incoming melody, while HS reflects harmonic stability. On all three, SongDriver is either the best system or essentially tied for best while still preserving the real-time constraint.
The ablation study is equally important. When the authors remove any one of the four musical features, performance drops across both objective and subjective metrics. That means the handcrafted feature layer is not decorative; it is a structural part of why the short-context Transformer works at all in a streaming setting.
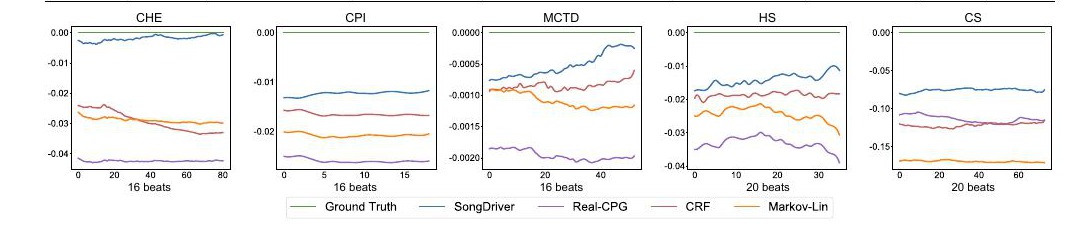
The bias-model comparison is especially telling. As the melody becomes longer, the SongDriver curve remains closest to ground truth across the plotted metrics, whereas Markov-Lin, Real-CPG, and plain CRF either drift steadily or fluctuate. This is exactly what one would expect if the cached arrangement signal is stabilizing the live decoder. In other words, the arrangement stage can be computed in parallel and cached, so the live path remains light without giving up structural consistency.
6. Why This Paper Matters
What makes SongDriver interesting is not only that it produces accompaniment in real time. The more important point is that it proposes a principled systems decomposition for streaming generation:
- use an expressive model for long-range musical planning;
- use a structured lightweight model for real-time execution;
- inject handcrafted global musical signals when the streaming context window is necessarily short.
That design pattern is useful beyond accompaniment generation. Any real-time generative system with long-horizon structure and strict latency constraints faces the same tension.
The main limitation is also visible from the design: part of the quality still depends on domain-specific feature extraction and rule-based texture patterns. But for a live accompaniment system, that is a reasonable engineering trade-off rather than a weakness to hide.
Publication
- Conference: Proceedings of the 30th ACM International Conference on Multimedia (MM ‘22)
- Pages: 1057-1067
- DOI: 10.1145/3503161.3548368