Why Agentic Design is Necessary for Data Analytics
Authors: Yikai Wang
1. The Central Question
This paper asks a precise systems question: when data-analytics tasks are multi-step and multi-task, can a standalone LLM inference pipeline ever be enough, or is agentic design structurally necessary?
The paper defines the two modes clearly:
- standalone inference: feed the prompt into a pretrained or post-trained LLM and take the output directly, without reasoning loops or tool calls;
- agentic inference: allow planning, decomposition, verification, and tool use at inference time.
The claim is not merely empirical. The paper argues that in multi-task data analytics, standalone inference has a representation bottleneck that standard pre-training and post-training do not resolve.
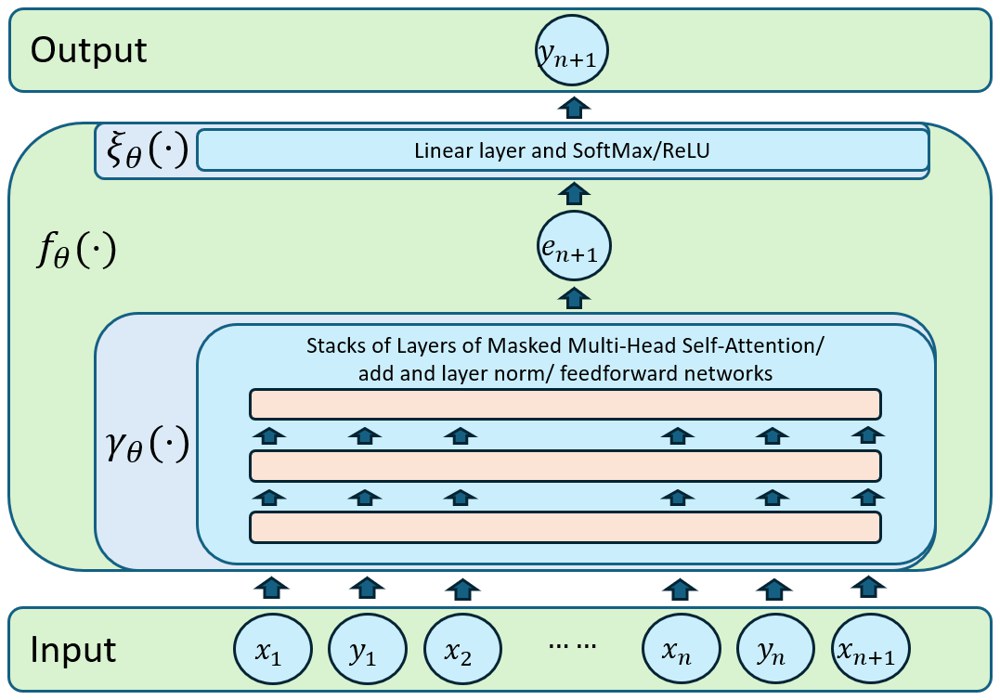
2. Formal Setup: Multi-task Analytics as Prompt-conditioned Learning
The paper studies prompts of the form
where the pairs (x_i, y_i) come from some underlying task f, and the model is expected to output y_{n+1} = f(x_{n+1}).
In a single-task setting, a sufficiently trained Transformer can do surprisingly well at this kind of in-context learning. The interesting question is what happens when the task itself is sampled from a mixture distribution, for example:
- linear regression,
- quadratic regression,
- classification.
Now the model must do two things at once:
- infer the task type from the prompt;
- solve the task conditional on that inferred type.
The paper argues that this first step is exactly where standalone inference breaks down.
3. The Representation Bottleneck in Standalone Inference
To make the argument analyzable, the paper abstracts a Transformer-based standalone LLM as
where is the prompt representation produced by the Transformer stack and is the relatively simple output head. Once written in this way, the weakness becomes clear: all prompts from all tasks must first be mapped into one shared representation space.
If prompts from different task families are not well separated in that space, then the output head cannot consistently apply the correct task rule. In other words, downstream prediction quality depends on whether the penultimate representation carries task identity cleanly enough.
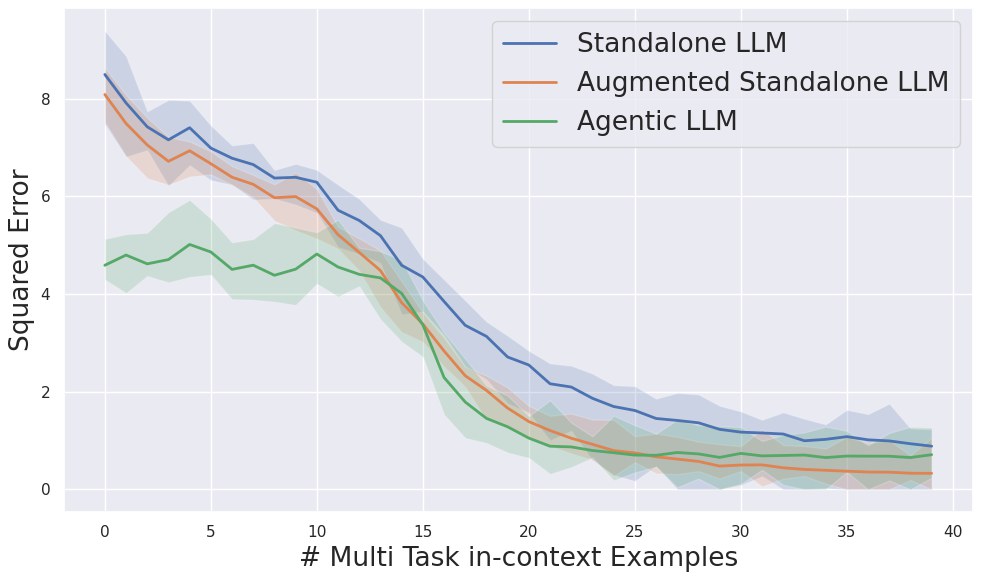
The experiments support exactly this diagnosis. The authors take embeddings from the penultimate layer and train a classifier to predict the task type. The task classification accuracy is only slightly above random guessing in the multi-task environments considered. That means the representation is already too entangled before the final prediction stage.
4. Why Standard Pre-training and Post-training Do Not Fix the Problem
The paper then makes a stronger claim: the failure is not repaired by the usual training upgrades.
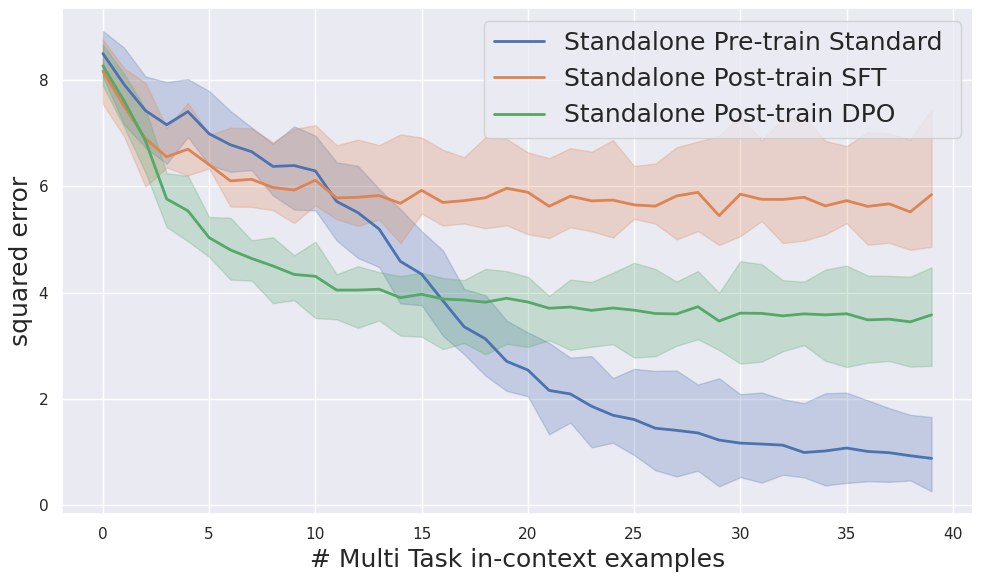
Under the standard pre-training pipeline, the model minimizes the main prediction loss on prompts sampled from a mixture of task distributions. But the training objective does not explicitly reward task identification. So the model can converge to an averaged representation that is adequate on aggregate and still poor at separating tasks.
This leads to the paper’s theoretical conclusions:
- when task embeddings are not well separated, the achievable downstream loss has a nontrivial lower bound;
- post-training can improve the task classification rate slightly, but not in a stable enough way to restore downstream performance;
- in some reported settings, post-training actually worsens the downstream analytics behavior relative to pre-training.
This is a sharp result because it pushes back on a common assumption that more SFT or RLHF should eventually solve everything. The paper’s argument is that if the representation itself is wrong for multi-task analytics, post-training only moves the output head around a flawed latent geometry.
5. Agentic Design Works Because It Avoids the Need for One-shot Task Compression
The paper does not attempt a full theorem for agentic systems, and that is reasonable because there is no single canonical agentic architecture. But the conceptual advantage is clear.
An agentic system does not need to encode the entire multi-task decision process into one latent vector and one direct output. Instead, it can:
- inspect the prompt;
- infer the likely task class;
- decide which operation or tool is needed;
- verify intermediate results;
- re-plan if the previous step was wrong.
That decomposition removes the main burden placed on rho_omega(P) in standalone inference. The model no longer has to solve the whole task-selection-and-solution pipeline in one irreversible pass.
In data analytics, that matters because tasks are rarely atomic. Cleaning, transformation, model selection, estimation, and interpretation are chained operations. Agentic design is therefore not an aesthetic preference. It is a way to avoid a brittle compression bottleneck.
6. The Alternative Proposed in the Paper: Auxiliary Loss During Pre-training
The paper does explore a non-agentic repair strategy. If the pre-training data includes task labels , add an auxiliary classifier on top of the learned representation and optimize
This augmented objective explicitly teaches the model to separate tasks in representation space while still solving the original predictive objective.
Empirically, this works in the expected direction. Task classification from the learned embeddings improves, and downstream predictive performance improves as well.
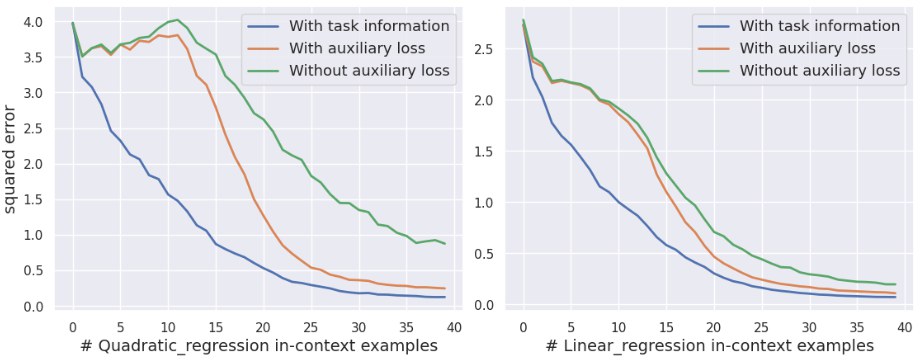
But the paper is careful here. Even with the improved pipeline, standalone inference still remains weaker than a simple agentic approach. So the alternative loss is not presented as a replacement for agents. It is presented as evidence for why the standard non-agentic pipeline is mismatched to the task.
7. Additional Evidence: Task-mixture Imbalance and Averaging Behavior
The later experiments strengthen the story in two ways.
First, the relative proportions of tasks in the pre-training distribution influence downstream performance. That means standalone inference is sensitive to how much each task family is represented during pre-training, which is exactly what you would expect if the model is learning an average latent compromise rather than a clean routing mechanism.
Second, in the two-task regression environment, the paper shows that the standard pipeline behaves like an average of the task-specific Bayes estimators instead of recognizing which estimator should be active. The auxiliary-loss pipeline tracks the correct estimator more closely.
This is a very nice result because it turns the representation argument into something observable. The model is not just wrong. It is wrong in a very specific way: it averages across incompatible task structures.
8. Why This Paper Matters
The main value of this paper is that it turns a vague engineering intuition into a much sharper diagnosis. People often say “agents work better for analytics,” but that statement by itself is too loose. This paper argues that the real bottleneck is task identification inside the latent representation of a standalone model.
That is a much more specific claim than “agents can use tools.” The paper says that when many task families are mixed together, one-shot standalone inference fails because the model does not cleanly separate task identity before making the final prediction. Once that separation fails, no amount of clever prompting at inference time is likely to rescue the downstream answer consistently.
The auxiliary-loss experiments are important for exactly that reason. They are not presented as a production replacement for agents; they act as a diagnostic intervention. When task separation is explicitly rewarded during training, standalone performance improves. That strengthens the paper’s causal story that the core failure mode is representational rather than merely due to insufficient scale or weak post-training.
The concrete takeaway is:
- multi-task analytics requires implicit task identification;
- standard standalone LLM training does not encourage clean task separation in representation space;
- therefore standalone inference remains structurally limited;
- agentic design is the practical answer, unless one is willing to redesign pre-training itself.
So this is not just a benchmark paper saying “agentic is better.” It is a representation-learning argument about why the gap appears and why analytics workloads are a particularly bad fit for a one-pass standalone pipeline.